View가 그려지는 과정
뷰는 포커스를 얻으면 레이아웃을 그리도록 요청한다. 이때 레이아웃의 계층구조 중 루트 뷰를 제공해야한다. 따라서 그리기는 루트노드에서 시작되어 트리를 따라 전위 순회 방식으로 그려진다. 부모 뷰는 자식 뷰가 그려지기 전에(즉, 자식 뷰 뒤에) 그려지며 형제 뷰는 전위 방식에 따라 순서대로 그려진다. 레이아웃을 그리는 과정은 측정(measure)단계와 레이아웃(layout)단계를 통해 그려지게 된다.
measure(int widthMeasureSpec, int heightMeasureSpec)
부모노드에서 자식노드를 경유하며 실행되며, 뷰의 크기를 알아내기 위해 호출된다. 이것은 뷰의 크기를 측정하는 것은 아니며 실제 크기 측정은 onMeasure(int, int)를 통해 이뤄진다. measure(int, int)의 내부에서는 onMeasure(int, int)를 호출함으로써 뷰의 크기를 알아낸다.
측정 과정에서는 부모 뷰와 자식 뷰간의 크기정보를 전달하기 위해 2가지의 클래스를 사용한다.
ViewGroup.LayoutParams
자식 뷰가 부모 뷰에게 자신이 어떻게 측정되고 위치를 정할지 요청하는데 사용된다.
ViewGroup의 sub class에 따라 다른ViewGroup.LayoutParams의 sub class가 존재할 수 있다. 예를 들어ViewGroup의 sub class인RelativeLayout경우 자신만의ViewGroup.LayoutParams의 sub class는 자식 뷰를 수평적으로 또는 수직적으로 가운데정렬을 할 수 있는 능력이 있다.
- 숫자 (ex. android:layout_width=”320dp”)
- MATCH_PARENT (ex.android:layout_width=”match_parent”)
- WRAP_CONTENT (ex.android:layout_width=”wrap_content”)
ViewGroup.MeasureSpec
부모 뷰가 자식 뷰에게 요구사항을 전달하는데 사용된다.
- UNSPECIFIED - 부모 뷰는 자식 뷰가 원하는 치수대로 결정한다.
- EXACTLY - 부모 뷰가 자식 뷰에게 정확한 크기를 강요한다.
- AT MOST - 부모 뷰가 자식 뷰에게 최대 크기를 강요한다.
layout(int l, int t, int r, int b)
부모노드에서 자식노드를 경유하며 실행되며, 뷰와 자식뷰들의 크기와 위치를 할당할 때 사용된다. measure(int, int)에 의해 각 뷰에 저장된 크기를 사용하여 위치를 지정한다. 내부적으로 onLayout()를 호출하고 onLayout()에서 실제 뷰의 위치를 할당하는 구조로 되어있다.
measure()와layout()함수는 내부적으로 각각onMeasure()와onLayout()함수를 호출한다. 이것은 final로 선언된measure()와layout()대신onMeasure()와onLayout()을 구현(override)할 것을 장려하기 위해서이다.
뷰의 measure()함수가 반환할때, 뷰의 getMeasureWidth()와 getMeasureHeight()값이 설정된다. 만약 자식 뷰 측정값의 합이 너무 크거나 작을 경우 다시 measure()함수를 호출하여 크기를 재측정한다.
참조
View Lifecycle
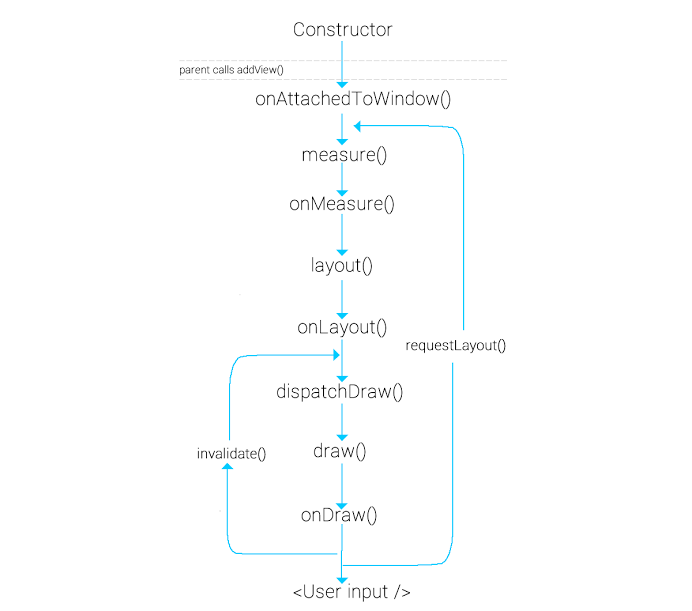
Constructor
모든 뷰는 생성자에서 출발합니다. 생성자에서 초기화를 하고, default 값을 설정합니다. 뷰는 초기설정을 쉽게 세팅하기 위해서 AttributeSet이라는 인터페이스를 지원합니다. 먼저 attrs.xml파일을 만들고 이것을 부름으로써 뷰의 설정값을 쉽게 설정할 수 있습니다.
onAttachedToWindow
부모 뷰가 addView(childView)를 호출하고 나서 자식 뷰는 윈도우에 붙게 됩니다(attached). 이때부터 뷰의 id 를 통해 접근할 수 있습니다.
onMeasure
뷰의 크기를 측정하는 단계입니다. 매우 중요한 단계이며, 대부분의 경우 레이아웃에 맞게 특정크기를 가져야합니다. 여기에는 두단계의 과정이 있습니다.
뷰가 원하는 사이즈를 계산합니다.
MeasureSpec에 따라 크기와 mode를 가져옵니다.123456protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {int widthMode = MeasureSpec.getMode(widthMeasureSpec);int widthSize = MeasureSpec.getSize(widthMeasureSpec);int heightMode = MeasureSpec.getMode(heightMeasureSpec);int heightSize = MeasureSpec.getSize(heightMeasureSpec);}MeasureSpec의 mode를 체크하여 뷰의 크기를 적용합니다.12345678int width;if (widthMode == MeasureSpec.EXACTLY) {width = widthSize;} else if (widthMode == MeasureSpec.AT_MOST) {width = Math.min(desiredWidth, widthSize);} else {width = desiredWidth;}
onLayout
이 단계에서 뷰의 크기와 위치를 할당합니다.
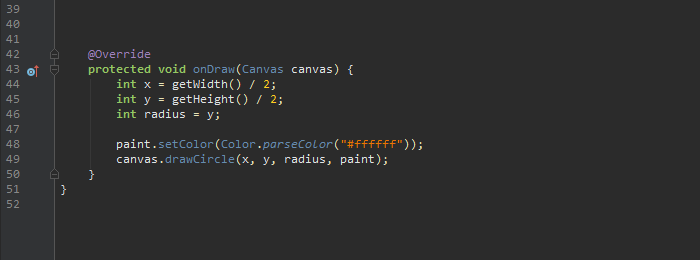
onDraw
뷰를 실제로 그리는 단계입니다. Canvas와 Paint객체를 사용하면 필요한 것을 그리게 됩니다. Canvas객체는 onDraw함수의 파라미터로 제공됩니다. Canvas을 이용하여 뷰의 모양을 그립니다. Paint객체는 뷰의 색을 그립니다.
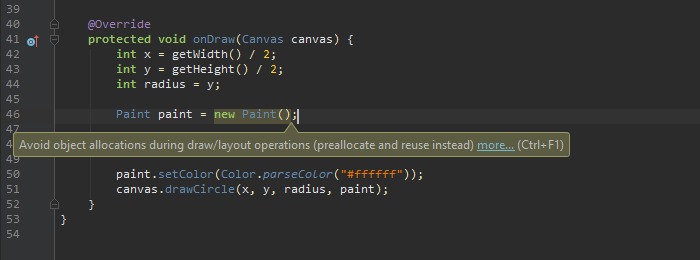
여기서 주의할 점은 onDraw함수를 호출시 많은 시간이 소요됩니다. Scroll 또는 Swipe 등을 할 경우 뷰는 다시 onDraw와 onLayout을 다시 호출하게 됩니다. 따라서 함수 내에서 객체할당을 피하고 한 번 할당한 객체를 재사용할 것을 권장합니다.
View Update
View Lifecycle을 보면 뷰를 다시 그리도록 유도하는 invalidate()와 requestLayout()함수를 볼 수 있습니다. 이것은 런타임에 뷰를 다시 그릴 수 있게 합니다. 각각의 사용 용도는 아래와 같습니다.
invalidate()
단순히 뷰를 다시 그릴때 사용된다. 예를 들어 뷰의 text 또는 color가 변경되거나 , touch interactivity가 발생할 때
onDraw()함수를 재호출하면서 뷰를 업데이트한다.requestLayout()
onMeasure()부터 다시 뷰의 그린다. 뷰의 사이즈가 변경될때 그것을 다시 재측정해야하기에 lifecycle을onMeasure()부터 순회하면서 뷰를 그린다.
Animation
뷰의 animation은 frame단위의 프로세스입니다. 예를 들어 뷰가 점점 커질때 뷰를 한 단계씩 차례대로 커지도록 할 것입니다. 그리고 각 단계마다 invalidate()를 호출하여 뷰를 그릴 것입니다. 대표적으로 애니메이션에 사용하는 클래스는 ValueAnimator입니다.
|
|
참조
Activity Lifecycle
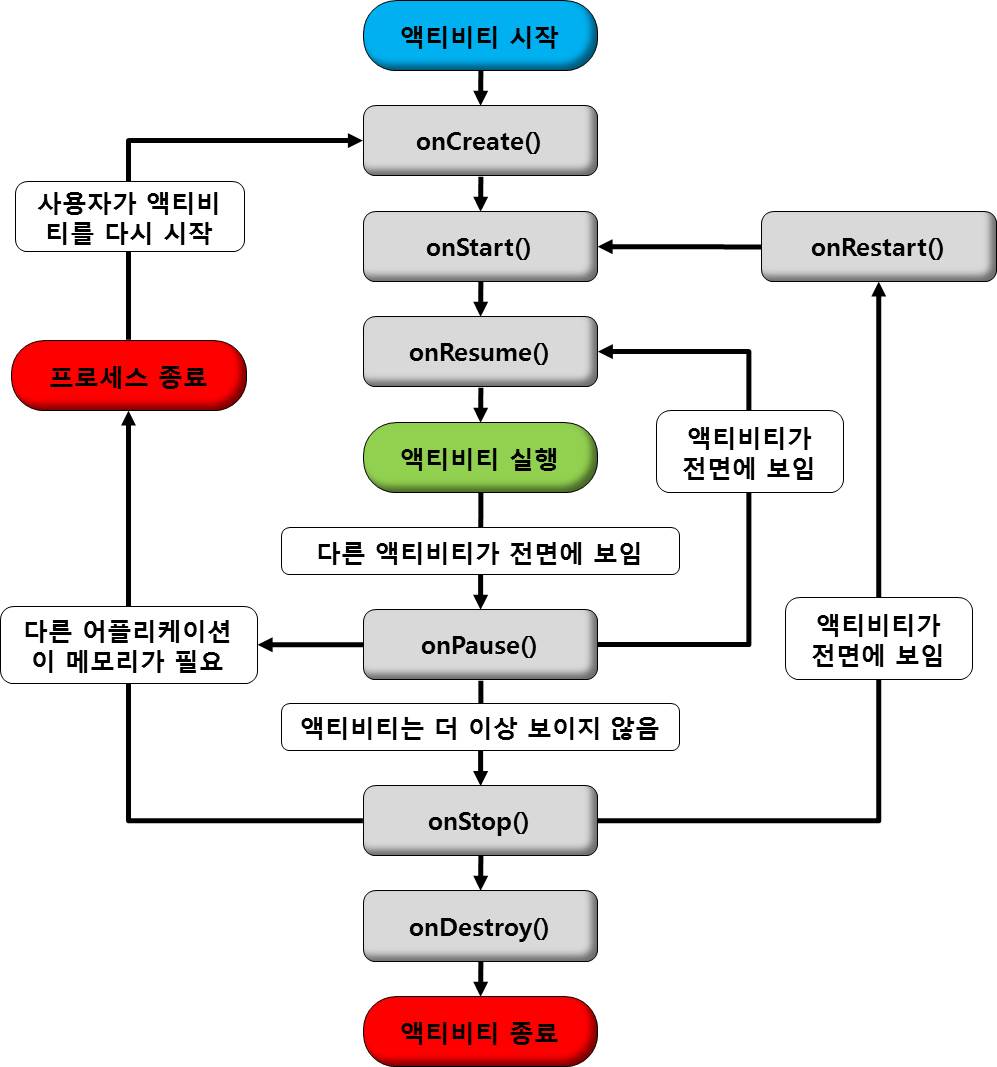
onCreate
액티비티가 처음 생성되었을 때 호출된다. 여기서 일반적인 정적 설정을 모두 수행해야 하며 이전 상태(intent)가 캡쳐된 경우 이것을 포함한 번들 객체가 전달된다. 항상 뒤에는 onStart가 따라온다.
onRestart
액티비티가 중단되었다가 다시 시작되기 직전에 호출된다. 항상 뒤에는 onStart가 따라온다.
onStart
액티비티가 사용자에게 보여지기 직전에 호출된다. 액티비티가 전경으로 나오면 onResume이 따라오고 액티비티가 숨겨지면 onStop이 따라온다.
onResume
액티비티가 화면에 보여지고 사용자와 상호작용하기 직전에 호출된다. 이 시점에 액티비티는 액티비티스택 최상단에 위치한다. 항상 뒤에는 onPause가 뒤따라온다.
onPause
다른 액티비티로 넘어가거나, 뒤로 가기를 누르거나, 홈으로 돌아가는 등 현재 액티비티가 사라지기 직전에 호출된다. 데이터를 유지하기 위해 저장하거나 스레드 중지 또는 앱이 종료되기 직전에 실행할 기능 등을 처리하기에 적당하다. 무슨 일은 하든 매우 빨리 끝내야 한다. 이 함수가 반환될때까지 다음 액티비티가 재개되지 않기 때문이다. 액티비티가 다시 전경으로 돌아오면 onResume이 뒤따라오고, 액티비티가 보이지 않게 되면 onStop이 뒤따라온다.
onStop
액티비티가 더이상 사용자에게 보여지지 않을 때 호출된다. 항상 호출되는 것은 아니며 메모리가 부족할 경우 호출이 안될 수 있다. 액티비티가 다시 전경으로 돌아오면 onRestart가 뒤따라오고 액티비티가 그대로 사라지면 onDestroy가 뒤따라온다.
onDestroy
액티비티가 소멸되기 직전에 호출된다. 호출이 안될 경우도 있기에 만약 액티비티가 종료되는 상황에 반드시 처리할 작업이 있다면 onPause에서 처리를 해야한다. 시스템이 비상 시에 메모리를 복구해야 할 경우, onStop과 onDestroy는 호출되지 않을 수도 있다. 따라서, 중요한 영구적 데이터를 보관할 경우 onPause()를 사용해야한다.
참조
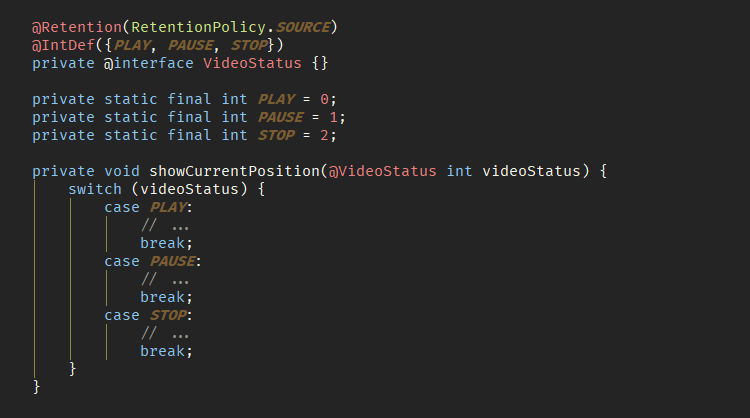
안드로이드에서 ENUM 사용을 자제시키는 이유
ENUM의 각 값은 객체이며, 각 선언은 단순히 객체를 참조하기 위해 런타임 메모리를 사용한다. 따라서 정수 또는 문자열 상수보다 더 많은 메모리를 차지하게 된다. 게다가 단일 ENUM을 추가하면 최종 DEX 파일 크기를 증가시키기에 런타임시 오버헤드가 발생할 수 있고, 앱의 크기가 증가하게 된다. 안드로이드에서는 ENUM 대신 TypeDef 어노테이션을 사용한다.
참조
대용량 Bitmap을 불러올 경우 메모리 문제를 해결하는 방법
createScaledBitmap(Bitmap bitmap, int width, int height)
비트맵을 생성할때 작은 크기로 생성하여 메모리 사용을 줄일 수 있다. 허나 이미 원본 비트맵이 메모리에 로드되어 있어야 리사이즈된 비트맵을 생성할 수 있는 단점이 있다.
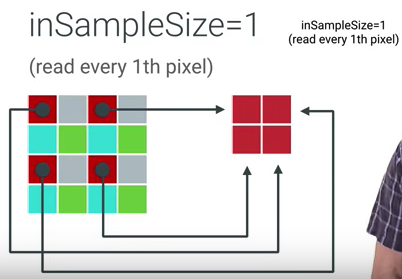
Bitmap.Options.inSampleSize
inSampleSize는 2의 지수 값만 가질 수 있으며, 2의 지수만큼 이미지를 작게만든다. inSampleSize크기만큼 픽셀을 건너뛰어 리사이징하기 때문에 속도가 매우 빠르다. 허나 2의 지수가 아닌 값으로는 리사이징을 못하는 단점이 있다.
Bitmap.Options.inScaled / Bitmap.Options.inDensity
어떠한 사이즈로든 리사이징이 되고 리사이징 필터가 적용되어 더욱 정교한 리사이징이 가능하다. 하지만 추가적인 필터단계는 많은 시간소요가 발생하기에 inSampleSize방법에 비해 느리다.
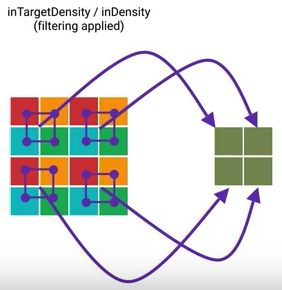
Combine inSampleSize & inScaled & inDensity
원하는 이미지 크기보다 2배 큰 이미지를 inSampleSize를 통해서 리사이징한다. (2의 지수만큼 리사이징이 가능하므로) 원하는 크기까지 inScaled와 inDensity를 이용하여 정교하게 리사이징하여 원하는 크기의 이미지를 얻는다.
Bitmap.Options.inJustDecodeBounds
원본 Bitmap 객체를 생성하지 않은 채로 원본 이미지 크기를 구할시 inJustDecodeBounds옵션을 이용한다. 이것의 값이 true일 경우 BitmapFactory.decodeFile(fileName, Options)를 통해 Bitmap을 생성시 Bitmap 객체를 반환하지 않고 Bitmap 정보를 Options 객체에 담는다. 따라서 Options.outWidth, Options.outHeight를 통해 너비와 높이를 알 수 있다. 반대로 Bitmap 객체를 생성하고 싶을 경우 inJustDecodeBounds 값을 false로 설정하여 decode하면 객체를 반환한다.
참조
String Literal
|
|
literal이란 쌍따옴표 안의 문자열을 말한다. 위 예제 1번처럼 literal을 통해 String객체가 생성되며, 2번과 같이 new 연산자를 통해 생성하는 String객체와는 내부적 구조가 조금 다르다. 자바에서 객체생성시 객체를 참조하는 변수(str)는 Stack 메모리, 객체는 Heap 메모리에 저장이 된다. 하지만 literal을 통해 생성된 String객체는 Heap 메모리에 저장이 되는 것이 아니라 별도의 공간인 String Constant Pool(상수풀)에 저장이 된다. literal은 값이 변하지 않는 immutable 클래스이며, 대신 이전에 생성했던 문자열을 중복 생성할시 SCP에서 해당 문자열을 불러와 참조하게 된다. 이 과정을 자세히 말하자면 소스파일(.java)이 .class 파일로 컴파일되고 이 파일이 JVM에 로드되면, JVM은 SPC에서 동일한 문자열이 있는지 확인할 것이다. 만약 동일한 문자열이 있으면 그것을 재사용하고 아닐경우 객체를 생성하며 SPC에 저장한다. 2번에서 new를 통해 “abc”객체를 생성하는 방법은 literal과 동일하다. 즉, SCP에서 문자열을 찾거나 새로 만들어서 이것을 참조한다. 하지만 new 연산자가 추가적으로 Heap에서 객체를 생성하여 문자열 literal을 참조한다. 따라서 2개의 객체가 생성되는 구조이다.
1번과 2번을 ==연산자로 비교하면 false가 나온다. 1번 객체는 SPC에서 가져온 객체이고 2번 객체는 Heap에서 가져온 객체이기에(문자열은 SPC에서 참조하지만 String객체는 Heap에 존재한다.) 단순 비교로는 false를 출력한다. 하지만 intern()함수를 사용하면 String객체가(Heap에 존재하는) 참조하는 실제 문자열(SPC에 존재하는)을 가져올 수 있다. 따라서 결과는 true를 반환하게 된다.
|
|
intern()함수는 SPC를 탐색해서 문자열이 존재하면 그것을 리턴하고 아니면 새로운 문자열을 SPC에 추가한 후 다시 반환한다. 따라서 new를 사용하건 literal을 사용하건 intern()함수를 사용하면 같은 문자열을 반환하게 된다.
참조
Medium - Java String 의 메모리에 대한 고찰
Java67 - Dfference between String literal and New String object in Java
: 글 내용보다 댓글논쟁이 치열하다
Annotation 생성방법 (관점프로그래밍)
클래스간 연관관계나 속성을 표현하기 위해 java 1.5 부터 추가되었스며, 소스 코드에 메타데이터를 표현하는 용도로 사용되었습니다. Annotation 에는 Java에 내장되어 있는 Built-in Annotation, Annotation에 사용되는 Annotation인 Meta-Annotation, 자신의 새로 정의하는 Custom Annotation이 있다.
Built-in Annotation
Java에 내장되어 있으며 주로 컴파일러에게 정보를 제공하기 위한 목적으로 사용된다.
- @Override
- 컴파일러에게 오버라이딩을 명시적으로 알림으로서 잘못된 메소드를 오버라이딩할 시 에러를 통해 알 수 있다.
- @Deprecated
- 더 이상 사용하지 말아야할 메소드를 나타낸다.
- @SuppressWarning
- 의도적으로 경고 메세지를 무시하도록 컴파일러에게 알린다.
- @FunctionalInterface
- 함수형 인터페이스라는 것을 알림으로써 실수를 미연에 방지하도록 한다.
Meta-Annotation
Annotation에 대해 정보를 설정하기 위한 Annotation이다.
- @Target
Annotation의 적용대상을 지정한다.
- @Retention
Annotation의 유지기간을 지정한다.- SOURCE - 소스파일에만 존재하며 컴파일 시점(클래스 파일)에서는 사라진다.
- CLASS - 클래스 파일에 존재하고 컴파일러에 의해 사용가능하지만 런타임시에는 사라지기에 JVM에서 사용이 불가하다.
Retention의default값이다. - RUNTIME - 클래스 파일에 존재하며 런타임시에도 사용 가능하다. 런타임시
Reflection을 통해Annotation정보를 읽어 처리할 수 있다.
- @Documented
Annotation에 대한 정보가 javadoc에 포함되도록 한다.
- @Inherited
Annotation이 자식 클래시에도 상속된다. 자식 클래시에도 이Annotation이 붙은 것으로 인식된다.
Custom Annotation
@interface를 통해 Annotation을 정의할 수 있다.
|
|
예제에서 선언한 MyAnno는 Custom Annotation이다. Field로 String을 가지고 있다. Retention을 Runtime으로 선언함으로서 런타임시에도 사용가능하도록 하였으며 Target을 Field와 Method로 설정함으로써 멤버변수와 함수에 적용가능하도록 설정하였다. main함수를 보면 MyClass의 name멤버변수에 MyAnn Annotation을 적용하였다. my객체의 최초 name값은 “Austen”이었지만, Reflection을 사용하여 MyAnno를 통해 받아온 String값을 name변수에 적용하였더니 출력값이 “This is Sample”로 변경됨을 확인할 수 있다.
참조
프로세스와 스레드의 차이
프로그램이 메모리에 올라가 실행되면 프로세스라고 부른다. 프로세스는 운영체제로부터 메모리와 CPU를 할당 받게 된다. 스레드는 프로세스 내에서 동작하는 실행 흐름을 말한다. 따라서 스레드끼리 프로세스 내의 스택을 제외한 자원을 공유할 수 있다. 기본적으로 하나의 프로세스가 실행되면 하나의 스레드가 실행된다. 이것을 메인 스레드라고 부르며, 안드로이드에서는 UI 스레드라고 부른다.
여러 프로세스를 통해 작업을 하지 않고 스레드를 사용하는 이유
첫번째, 프로세스간 자원을 공유하지 않는다. 프로세스는 자신만의 메모리영역이 존재하고 이것은 다른 프로세스에서 접근이 불가능하다. (프로세스간 자원공유 설명필요…)
두번째, 프로세스의 생성은 많은 자원과 메모리가 사용되므로 비용이 크다. 프로세스가 실행되려면 메모리에 올라와야하므로 비용이 크다.
세번째, 다른 프로세스에게 CPU를 넘기는 Context Switch는 비용이 큰 작업이고, 시스템콜을 발생시키므로 시간이 오래걸린다.
따라서 여러 작업을 동시에 실행하기 위해서는 여러 스레드를 사용하여 비동기적인 실행을 하는 것이 더욱 효율적이다.
참조
Vector vs ArrayList vs LinkedList
Vector는 배열의 동적인 사용을 위해 Java 1.0 부터 제공되는 클래스이다. 내부적으로 synchronized를 통해 구현되어 있기 때문에 동기화를 보장한다. 하지만 멀티 스레드 환경에서는 성능이 현저히 떨어지기 때문에 List인터페이스를 주로 사용한다. ArrayList와 LinkedList는 List인터페이스를 구현한 Collection구현체이다. List인터페이스는 기본생성시 동기화를 보장하지 않지만 동기화가 필요한 환경에서는 Collections클래스를 통해 동기화를 보장할 수 있다.
|
|
ArrayList
내부적으로 데이터를 배열에서 관리하며 추가, 삭제시 임시 배열을 생성하여 데이터를 복사하는 구조이다. 따라서 대량의 자료를 추가, 삭제할 시 메모리 소모가 크고, 시간이 오래걸려 성능저하가 발생하며, 사이즈가 고정되어 있기때문에 사이즈를 초과할시 사이즈가 늘어난 배열을 생성하여 데이터를 옮겨야하기에 복잡한 연산과 메모리가 필요하다는 단점이 있습니다. 하지만 데이터마다 인덱스를 가지고 있기 때문에 검색에 뛰어나다.
LinkedList
데이터를 노드에 저장하고 노드간 양방향 연결을 통해 데이터를 추가, 삭제하는 구조이다. 따라서 추가, 삭제가 빠른 장점이 있지만, 검색시 노드를 처음부터 순회해야 하기 때문에 비교적 느리다는 단점이 있다.
참조
Quick Sort
특정 원소를 pivot으로 설정하여 pivot 앞에는 작은 값, 뒤에는 큰 값들을 위치시킨다. 둘로 분할된 리스트는 각각 앞의 과정을 재귀로 반복실행하여 정렬하는 과정이다. 시간복잡도는 최악이 O(n^2)이고, 평균 O(nlogn)이다. 최악의 상황은 항상 pivot을 최댓값 또는 최솟값으로 선택한 경우로서 매번 정렬된 원소들이 한쪽에 치우치게 되어 비교연산을 n^2번 하기 때문이다.
|
|
참조
다형성(Polymorphism)이란
사전적 의미로는 같은 생물종이지만 모습이나 특징이 고유한 성질을 가지는 것을 말하며, 관용적인 의미로는 클래스나 메소드가 다양한 형태로 사용되는 것을 말한다. 즉, 자바에서 다형성은 같은 객체이지만 다양하게 구현되어 각자 고유한 성질을 가지는 객체로 사용되는 것을 말한다. 대표적으로 Override와 Overload, Interface가 있다. 이런 관점에서 보았을때 Generic을 다형성으로 표현하기 어렵다.
참조
Iterator를 쓰지 않고 직접 참조 시 문제점
Iterator는 내부 구현에 대한 이해 없이 데이터를 순차적으로 탐색할 수 있도록 지원하는 인터페이스이다. 데이터의 내부 구조를 모르더라도 next()함수를 통해 일관된 순차 탐색이 가능하다. LinkedList, HashMap을 구성하는 구체적인 자료구조(Node나 Entry)를 모르더라도 Iterator를 사용하면 원하는 정보를 가져올수 있다. 따라서 내부 구조를 숨길 수 있어 정보은닉 이 보장되고 Iterator 인터페이스를 각 자료구조에 맞게 오버라이딩함으로써 다형성을 보장한다. Iterator를 쓰지 않을 경우 다음과 같은 문제가 발생할 수 있다.
내부 구조가 노출되지 않아야하는 클래스로 구성된 리스트를 탐색할때 클래스가 탐색 기능을 지원하지 않는 한 탐색이 불가능하다. (정보은닉 문제)
Collection을 구현한 자료구조를 탐색할때 각각의 자료구조에 맞는 탐색 기능을 구현해야한다. (다형성 문제)특히,
LinekdList의 경우 데이터를 탐색할때 시간 복잡도가 O(n^2)이 나와 성능저하를 유발할 수 있다.12345678910111213141516171819202122232425// 예제for (int i = 0; i < linkedList.size(); i++) {if (linkedList.get(i) == "what i'm looking for") {System.out.println("Get Cha");}}// LinkedList.get(int index)public E get(int index) {checkElementIndex(index);return node(index).item;}// LinkedList.node(int index)Node<E> node(int index) {if (index < (size >> 1)) {Node<E> x = first;for (int i = 0; i < index; i++)x = x.next;return x;} else {Node<E> x = last;for (int i = size - 1; i > index; i--)x = x.prev;return x;}}위 예제는
index를 이용하여 찾고자하는 값까지 순차탐색하는 코드이다.LinkedList외부에서 값을 찾기위해 순차탐색을 하지만LinkedList내부에서도 해당index까지 접근하기 위해 순차탐색을 하는 것을 볼 수 있다.LinkedList의 인덱스에 접근하기 위해서는head부터index까지 순차탐색을 해야하기 때문이다. 따라서LinkedList는 순차탐색시iterator를 이용한 접근을 해야된다.
참조
제네릭이란
클래스 내부에서 사용할 데이터 타입을 외부에서 지정하는 기법이다. 제네릭을 사용하는 이유는 확장성과 타입 안전성 때문이다. 기능을 구현할때 제네릭을 사용하면 다양한 자료형에 적용이 가능하여 확장성을 보장할 수 있다. 이러한 특징은 Object를 통해서도 보장이 가능하지만 Object는 타입에 대한 검사가 이뤄지지 않기 때문에 컴파일 타임에 문제를 인지할 수 없다. 따라서 잘못된 타입이 적용되었을 경우 에러를 잡기가 힘들다. 반면 제네릭은 사용하고자하는 자료형을 명시적으로 표시함으로써 잘못된 자료형을 컴파일타임에 찾을 수 있다. 비록 제네릭은 생략될 수 있기 때문에 명시적인 자료형 선언 없이도 사용이 가능하여 타입 안전성이 무너질 수 있으나 컴파일이 경고를 통해 타입 안전성이 깨진다는 메세지를 보냄으로써 문제 유발 가능성을 알 수 있다.
참조
Singleton 동기화
클래스에서 하나의 객체만 생성하여 사용하도록 제한하는 디자인패턴이다. 하나의 객체만 관리하여 요청을 차례대로 처리해야하는 Thread Pool이나 Datebase Connection Pool 같은 경우 사용되며 객체를 생성하는데 비용이 큰 객체의 경우, 하나의 객체를 재사용함으로써 메모리 사용을 줄이고 객체 로딩 시간을 줄일 수 있다.
문제점
Singleton객체를 사용하는 클래스간 결합도가 높아지기에 테스트가 어렵고, 에러를 잡기가 어려워진다. 또한 멀티 스레드 환경에서 데이터 동기화문제가 발생한다. 메모리 반환도 제대로 이루어지지 않기 때문에 너무 많은 사용은 오히려 메모리 소모가 많을 수 있다.
참조
What is the difference between all-static-methods and applying a singleton pattern
Singleton Design Pattern - When To Use Static Class In Place Of Singleton In Java
정적 클래스(메소드)와 Singleton차이
Singleton클래스는 객체를 함수에 파라미터로 전달할 수 있고, 일반 객체처럼 다룰 수 있다. 정적 클래스는 오로지 정적 메소드에 대한 접근만 허용한다. 정적 메소드는 단순 사용만 가능하지만 Singleton클래스는 다른 클래스를 상속할 수 있고, 상속될 수 있어 확장성이 크다.
Singleton사용시 멀티 스레드 환경에서 동기화 문제 해결하기
Lazy initialization(게으른 초기화)
instance를 private static으로 선언한 후 getInstance()함수에 synchronized키워드를 적용하여 thread-sate하게 만든다. 하지만 getInstance() 접근할때마다 synchronized가 발생하여 성능저하를 유발한다.
|
|
Lazy initialization + Double-checked locking
getInstance()에 synchronized를 사용하는 것이 아니라 getInstance()함수 안에서 if문으로 instance존재 여부를 체크한 후 null이면 여기서부터 synchronized를 사용하여 이후 작업을 동기화시킨다. synchronized안에서 다시 instance를 null체크하여 객체를 생성할지 말지 결정한다. 이 방법으로 인해 처음 Singleton클래스가 객체 생성이후 synchronized코드를 타지 않기 때문에 성능저하를 완화할 수 있다. 하지만 out-of-order 쓰기로 인해 완전히 초기화되지 않은 객체를 반환할 수 있다. 이것은 다음과 같은 진행으로 문제가 발생한다.
- 첫 스레드가 1번 코드를 지나고 2번 코드에 진입한다.
- 첫번째 스레드는 다시 3번 코드을 지나 4번 코드에 의해 객체를 생성하던 중 생성자를 호출하기 전에 두번째 스레드에 선점된다.
- 두번째 스레드는 1번 코드에서 객체를 반환받는다.
instance는 _nonnull 상태이기에 객체를 리턴한다. 하지만 객체는 완전한 초기화가 진행되지 않은 상태의 객체이다. - 다시 첫번째 스레드에 선점되고 초기화가 완료된 후 완전한 객체가 반환된다.
이런 문제는 volatile로 인해 해결이 가능하다. volatile 로 선언한 변수는 스레드 로컬에 캐시되지 않고 메모리에 바로 읽고 쓰기를 실행하며, 읽고 쓰는 작업이 atomic 하게 이루이진다. 따라서 4번 코드를 실행할시 객체 할당이 완료될때까지 다른 스레드에 선점되지 않는다.
|
|
참조
Singleton, Lazy loading 그리고 WeakSingleton
Eager initialization
앞의 방식은 getInstance()함수 호출시 객체를 초기화한 것에 반해 이것은 클래스가 로드되는 시점에 객체를 미리 생성하는 방식이다. 이것을 이해하기 위해 클래스의 static 필드가 초기화되는 시점과 객체가 초기화되는 시점을 알아야한다. 클래스의 초기화는 클래스 단위와 객체 단위가 있다. 클래스 단위의 초기화는 클래스를 처음 호출하는 시점에(클래스 초기화 조건에 만족하는 순간) 단 한번 이루어지며 static으로 선언된 멤버변수나 초기화 블럭이 실행된다. 여기서 실행된 정보는 Runtime Data Area 중 Class(Method) Area에 저장된다. 클래스 단위 초기화(static)가 이루어지는 시점은 로드 타임에 일어난다. 로드 타임은 메모리에 올라오지 않은 클래스를 처음 접근할때 클래스 로더가 해당 클래스 정보를 메모리(Class Area)에 올리는 시점을 말한다. 이 시기는 처음 프로그램이 시작하는 시기일 수도 있고 프로그램이 진행하는 시기일 수도 있다. 클래스 로더가 클래스를 메모리에 올리는 순서는 다음과 같다.
- 어떤 메소드를 호출하는 문장을 만났는데, 그 메소드를 가진 클래스 바이트코드가 아직 로딩된 적이 없다면, 곧바로 JVM은 JRE라이브러리 폴더에서 클래스를 찾는다.
- 없으면, CLASSPATH 환경변수에 지정된 폴더에서 클래스를 찾는다.
- 찾았으면 그 클래스 파일이 올바른지 바이트코드를 검증한다.
- 올바른 바이트코드라면 메소드영역으로 파일을 로딩한다.
- 클래스 변수를 만들라는 명령어가 있으면 메소드 영역에 그 변수를 준비한다.
- 클래스 블록이 있으면 순서대로 그 블록을 실행한다.
- 한번 클래스의 바이트코드가 로드되면 JVM이 종료될때까지 유지된다.
참조
객체 단위의 초기화는 객체를 생성할때마다 해당 객체별로 초기화가 이루어지며 멤버 변수와 초기화 블럭이 실행되고 다음으로 생성자 내의 코드가 실행된다. 여기서 발생하는 데이터는 Heap Area에 저장이 된다. 객체 단위 초기화가 이루어지는 시점은 런타임이다. 초기화과정을 알았으면 초기화가 일어나는 조건을 알아야한다. 클래서 초기화가 이루어지기 위해서는 다음의 조건에 만족해야 한다.
클래스의 인스턴스가 생성될 때(생성자 호출) - 클래스 초기화, 객체 초기화
클래스에서 선언한 정적 필드(
static으로 선언된 멤버변수나 멤버함수)가 호출되었을 때 - 클래스 초기화, 멤버 변수가 생성자를 호출할 경우(eager initialization) 객체 초기화도 발생특히, 클래스에서 호출하는 정적 멤버변수는
fianl이 아니어야 된다. - 2번에 대한 예외사항이다.final로 선언된 정적 변수 즉, 상수는 클래스가 로드되는 시점이 아닌 컴파일 시점에 초기화가 일어난다. 외부에서 클래스 내 상수 변수에 접근한다면(ex.Singleton.finalValue) 클래스 초기화가 일어나지 않고 해당 변수값만 가져오게 된다. 따라서 정적 멤버변수가final로 선언되었다면 아무런 초기화가 발생하지 않는다. 컴파일 타임에 초기화되는 상수의 조건은 다음과 같다.final로 선언되어 있다.- 타입이 기본형이거나
String이어야 한다. - 접근자가
public이어야 한다. - 선언과 동시에 초기화 된다.
- 상수로 초기화가 되어야 한다.
위의 조건에 만족하는 멤버변수는 컴파일 타임에 초기화가 이루어진다.
참조
이러한 조건에 따라 클래스의 초기화가 일어나며 객체가 생성되었느냐 아니냐에 따라 클래스 단위의 초기화만 일어날지 아니면 객체 단위의 초기화까지 일어날지가 정해진다. 그렇다면 앞전의 Singleton예제 같은 경우 lazy initialization 이라고 하였는데 이것은 클래스 초기화가 런타임에 이루어지는 것을 말한다. 자세히 설명하자면 getInstance()를 호출함으로써 함수를 실행하기 전에 클래스 로더가 Singleton클래스를 메모리에 로드시키고 Singleton클래스는 클래스 단위의 초기화를 시작한다. 여기서 static영역은 instance 이기에 이 참조변수를 Class Area 에 저장한다. 아직 객체를 할당한 것(new Singleton)은 아니기에 객체단위 초기화는 일어나지 않는다. 이제 클래스 초기화 단계는 끝이 나고 getInstance()함수를 실행한다. 실행 중 객체를 할당하는 new Singleton() 명령을 실행하는 순간 객체 단위 초기화가 이루어진다. 여기서 객체 단위 초기화가 이루어지면서 생성자가 실행되고 객체가 할당되기 때문에 lazy initialization 이라고 부르며 초기화 작업이 완료된다. 반대로 eager initialization 은 로더 타임에 instance 가 객체 할당까지 되므로 객체 단위 초기화가 일어나면서 생성자도 호출하면서 초기화를 완료하기에 eager라 부르며 이것이 클래스 로드 타임에 이루어진다. eager initialization 은 동기화와 성능저하 문제를 해결할 수 있다. 사실상 객체 초기화 시기가 다르다고 말을 하지만 시기상(getInstance()함수를 호출하여 초기화하기까지) 거의 차이가 없다. eager 보다 장점이 있다면 lazy 는 초기화 과정에서 멤버변수를 초기화하거나 멤버변수를 사용할 수 있다. 만약 멤버필드를 사용해서 처리할 작업이 있다면 lazy initialization 방식을 사용해야된다.
|
|
참조
자바 로드타임 로딩 및 런타임 로딩 이해하기(ClassLoader)
Using Enum
Java 1.5부터 Enum을 사용하여 Singleton클래스를 간단하게 구현할 수 있다. Enum은 명확하게 thread-safe를 보장할 뿐 아니라 JVM에 의해 Serialization이 보장되며 많은 양의 코드를 줄일 수 있다.
|
|
Initialization on demand holder idiom (holder에 의한 초기화)
클래스 안에 클래스(Holder)를 두어 JVM의 Class Loader 메커니즘에 의해 Class가 로드되는 시점을 이용한다. Singleton클래스 안에 private static으로 선언된 Holder 클래스를 정의하고 클래스 내부에 public static final로 선언된 Singleton instance 를 생성한다. getInstance()함수는 내부에서 Holder클래스의 객체를 반환하는 구조로 설계함으로써 Singleton객체 초기화작업을 Holder클래스가 로드될때 Class Loader 에 위임하여 원자성을 보장한다. getInstance()가 호출될때까지 Singleton클래스 내 static 영역은 초기화가 되지만 객체는 생성되지 않는다. getInstance()함수가 호출되면 객체를 감싸고 있는 LazyHolder 클래스가 참조되고 이 시점에 Class Loader 가 LazyHolder클래스를 메모리에 올리면서 클래스 단위 초기화를 진행한다. static으로 선언된 Singleton객체는 비로서 Class Loader에 의해 생성된다. lazy initialization을 사용하기에 메모리 사용이 효율적이고, synchronized키워드를 사용하지 않기에 성능 저하 문제도 발생하지 않는다. 이것은 Class Loader 의 동기화 속성에 의해 가능한 일인데 만약 여러 스레드가 getInstance()에 동시 접근할시 JVM은 클래스를 초기화하기 위해 필드 접근을 동기화하게 되고 이때 Singleton객체가 생성되면 그 다음부터의 접근은 생성된 객체를 참조하게 된다.
|
|
Singleton and Serialization
Serialization은 자바 프로그램 내의 객체 또는 데이터를 외부의 자바 시스템에도 사용할 수 있게 바이트형태로 변환하는 기술과 변환된 데이터를 다시 객체로 변환하는 기술을 아울러 말한다. 그러나 직렬화(Serialization)한 객체를 여러번 역직렬화(Deserialization)하면 Singleton객체가 여러개 생산될 수 있는 문제가 발생한다. 이러한 이유때문에 readResolve()라는 함수를 Singleton클래스 안에 구현해야하며, 이 함수를 통해 역직렬화가 완료된 후 생성된 유일한 객체를 반환하도록 보장할 수 있다. 역직렬화시 ObjectInputStream 객체에 readObject()를 호출함으로써 객체를 생성한다. readObject()는 파라미터가 없는 기본생성자를 호출함으로써 객체를 생성하므로 역직렬화를 반복하면 여러개의 Singleton객체가 생성될 수 있다. readResolve()를 구현하면 객체를 생성할때 readObject() 대신 readResolve()함수를 쓰게 되다. 따라서 생성된 정적 객체를 반환하도록 구현하면 역직렬화를 반복하더라도 유일한 객체 생성을 보장할 수 있다.
|
|
참조
Always Start With Eager Initialization
우아한 형제들 - 자바 직렬화, 그것이 알고싶다. 훑어보기편
StackOverFlow - Java serialization: readObject() vs readResolve()
How are constructors called during serialization ans deserialization
이 포스트가 도움이 되었다고 생각하시면, 위의 버튼을 클릭하여 후원해주세요.
이 포스트를 공유하려면 QR 코드를 스캔하세요.